在这个树莓派 Snowboy 项目中,我们将向您展示如何在 Pi 上设置和使用 Snowboy 来训练和检测自定义热门单词。

此外,我们还将向您展示如何在 Python 脚本中利用 Snowboy 库来执行特定操作。
要设置 Snowboy Hotword 检测库,我们将引导您完成注册其 API 的过程。我们还将向您展示如何使用 Snowboys 培训服务来记录和培训自己的热词检测模型。
在本教程中,我们还将探索如何使用 Python 利用 Snowboy 的检测器来使用您的热词模型,并基于听到该词来做某些事情。
最重要的是,您可以将 Snowboy 设置为完全无头的解决方案,因为它不需要任何图形界面即可操作。
如果您喜欢这个项目,那么您可能还想看看我们的树莓派 Alexa 教程和树莓派上的 Google 助手教程。
您可以在下面找到有关如何在树莓派上设置 Snowboy 的完整教程。
设备
以下是完成此树莓派 Snowboy 教程所需的设备的完整列表。
推荐的
树莓派
Micro SD 卡
Ethernet Cord 或 * Wifi dongle (树莓派 3 已内置 WiFi) )
电源
USB 麦克风
发言人
可选的
树莓派外壳
USB 键盘
USB 鼠标
为 Snowboy 准备树莓派的音频配置
1 在开始在树莓派上设置 Snowboy Hotword 检测之前,我们必须首先确保已正确配置音频。
我们将通过为音频驱动程序创建配置来实现这一目标。
在执行此操作之前,我们必须检索音频输出和麦克风输入的卡号和设备号。
要检索我们需要的信息,请执行以下两个步骤。
1a。利用以下命令找到您的 USB 麦克风。写下卡号和设备号。
记录-l1b。首先,让我们找到扬声器。为此,我们将利用以下命令。写下卡号和设备号。
请注意,树莓派的 3.5mm 插孔通常标记为 Analog 或 bcm2835 ALSA 。 HDMI 输出被标识为 bcm2835 IEC958/HDMI 。
播放-l2 现在,我们需要配置音频驱动程序的所有值,我们可以继续创建.asoundrc 文件。
要开始创建新的.asoundrc 文件,请在树莓派上运行以下命令。
vim /home/pi/.asoundrc3 在此文件中,我们需要输入以下配置行。这些将通过告诉我们应该使用的特定设备来设置我们的音频驱动程序。
请确保将”<卡号>” 和”< 设备号 >” 替换为在” 步骤 1 “中获取的相应值。
pcm。!默认{
类型不对称
capture.pcm"麦克风"
playing.pcm"扬声器"
}
pcm.mic {
型插头
奴隶 {
pcm"硬件:<卡号>,<设备号>"
}
}
pcm.speaker {
型插头
奴隶 {
pcm"硬件:<卡号>,<设备号>"
}
}4 插入行,然后进行更改。按 CTRL + X,然后按 Y ,最后按 ENTER 保存。
将 Snowboy 安装到树莓派
1 在将 Snowboy Hotword 检测软件安装到我们的树莓派之前,首先要确保它是最新的。
为此,您需要在树莓派上输入以下两个命令。
sudo apt update
sudo apt upgrade2 现在,我们的树莓派完全是最新的,现在通过运行以下命令安装我们将依赖的所有依赖项。
这些依赖的大部分都添加了”pyaudio” 包,该包使我们能够与 Python 的音频进行交互。
请注意,当我们为 Python 3 下载这些软件包时,您也可以通过在软件包名称中在”python” 之后删除”3” 来为 Python 下载它们。
sudo apt install python3 python3-pyaudio python3-pip libatlas-base-dev portaudio19-dev3 从包管理器中获取所有依赖项后,我们现在需要为 PortAudio 软件安装 python 绑定。通过在树莓派上运行以下命令,为 PortAudio 安装 python 绑定。
sudo pip3安装 pyaudio 4 对于我们的最终依赖性,我们将需要安装一个名为 request 的 Python 包,在树莓派上运行以下命令以使用 pip 进行安装。
这个 Python 套件可让我们与树莓派中的 Snowboy 的 Restful API 进行交互。此 Python 软件包将有助于将我们的热门示例发送给他们的服务。
sudo pip3安装请求5 最后,我们可以将 Snowboy 本身下载到我们的树莓派中。为此,请在树莓派上使用以下命令来获取树莓派的最新编译版本。
此版本的 Snowboy 应该可以在所有最新版本的树莓派上使用。
wget -O snowboy.tar.bz2 https://go.pimylifeup.com/napoRs/snowboy6 现在,我们已经在树莓派中获取了最新版本的 Snowboy 软件,我们需要通过运行以下命令将其解压缩。
发出以下命令时,请确保您位于 Pi 用户主目录中。 (/home/pi 或〜)
焦油 xvjf snowboy.tar.bz27 现已将 Snowboy 软件下载到我们的树莓派中,我们需要重命名目录,以便以后处理。
运行以下命令,将文件夹重命名为 snowboy 。
mv rpi-arm-raspbian-8.0-1.3.0/snowboy /获取 Snowboy API 密钥
1 对于本教程的下一部分,我们将需要 Snowboy 的 API 密钥。在接下来的几个步骤中,我们将引导您完成获取一个简单过程。
请注意,Snowboy 网站仅支持 OAuth 登录,因此您必须具有 Github ,Facebook 或 Google 帐户。
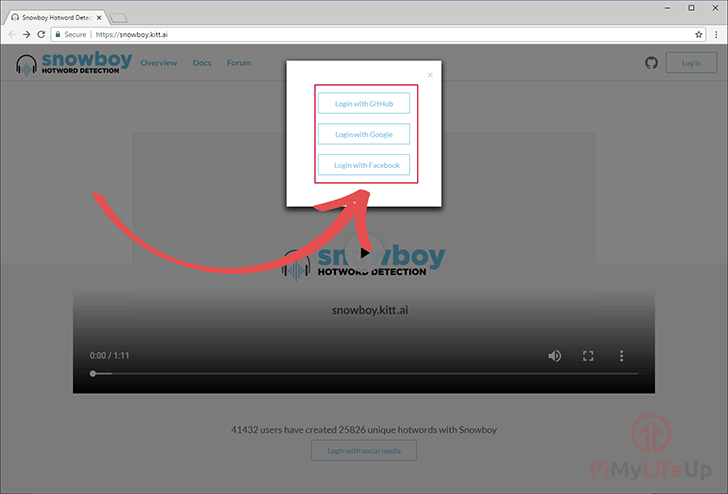
首先转到 Snowboy 网站并单击位于页面右上角的” 登录” 按钮,如下所示。

2 现在,您将被要求从三个不同的选项中进行选择,以登录到 Snowboy 服务,在本教程的整个过程中,我们仅使用了 Github 帐户。
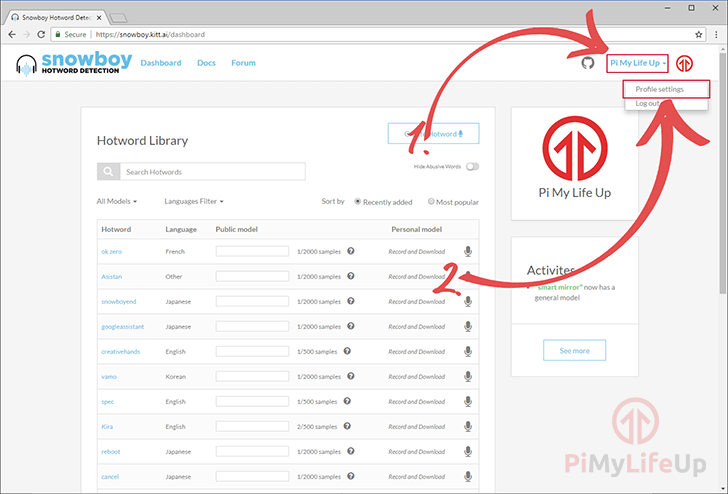
3 登录后,将显示以下屏幕,其中将列出所有当前正在计算的热门单词。但是,我们追求的是位于右上角。
单击您显示的名称 (1),然后单击” 配置文件设置”(2 ),这将带我们进入显示 API 密钥的页面。
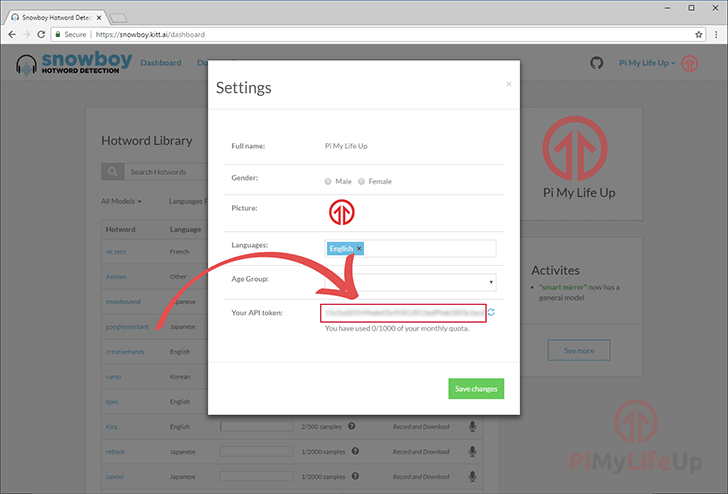
4 最后,在此屏幕上,您需要复制 API 令牌,因为需要此令牌才能与本指南后面的 Snowboy 服务器通信。
我们在下面的屏幕快照中突出显示了令牌将显示的区域。
记录 Snowboy 的自定义关键词
1 对于树莓派 Snowboy 教程的这一部分,我们需要编写一个 Python 脚本,该脚本会将我们的热词记录从树莓派发送到 Snowboy 服务。
我们不会过多地研究此脚本,因为它相对简单,并且只是本教程中的一小块垫脚石。
通过在树莓派上运行以下命令来创建此脚本。
vim /home/pi/training_service.py2 在此文件中,输入以下 python 代码行。
请记住,将”ENTER_TOKEN” 替换为您在上一段中检索到的 API 令牌,并将”ENTER_HOTWORD” 替换为您要记录的热门字词,例如”Pi My Life Up”。
导入系统
导入 base64
汇入要求
def get_wave(fname):
使用 open (fname,'rb')作为 infile 文件:
返回 base64 .b64encode(infile.read())
端点="https://snowboy.kitt.ai/api/v1/train/"
令牌="ENTER_TOKEN"
hotword_name ="ENTER_HOTWORD"
语言="en"
age_group ="20_29"
性别="M"
麦克风="usb麦克风"
如果__name__ =="__main__":
尝试:
[_,wav1,wav2,wav3,输出] = sys.argv
除了 ValueError :
打印("用法:%s wave_file1 wave_file2 wave_file3 out_model_name"%sys.argv [0])
sys.exit()
数据= {“名称”:hotword_name,
“语言”:语言,
“age_group”:age_group,
“性别”:性别,
“麦克风”:麦克风,
“令牌”:令牌,
“voice_samples”:[
{“wave”:get_wave(wav1)},
{“wave”:get_wave(wav2)},
{“wave”:get_wave(wav3)}
]
}
响应= requests.post(端点,json =数据)
如果 response .ok:
使用 open (out,"wb")作为 outfile :outfile.write(response.content)打印("将模型保存到'%s'。"%out)
其他:
打印("请求失败。")
打印(response.text)3 输入所有行后,请按 CTRL + X,然后按 Y ,然后按 ENTER 保存文件。
4 现在,我们已经写出了培训服务的 Python 脚本,我们可以继续实际记录要发送的热词。
为此,我们将使用”arecord” 工具,因为它允许我们指定特定的选项,例如采样率,记录的格式和持续时间。
对于我们的录制,我们将进行简单的 5 秒录制。这五秒钟应该足以记录我们的热词。
运行这些命令中的每一个,以生成我们的 3 个 Hotword 录音,并确保在录音过程中只说一次 Hotword 。
Snowboy 软件将使用这三个录音来创建参考文件,以便它可以轻松收听。
arecord --format = S16_LE --duration = 5 --rate = 16000 --file-type = wav 1.wav
arecord --format = S16_LE --duration = 5 --rate = 16000 --file-type = wav 2.wav
arecord --format = S16_LE --duration = 5 --rate = 16000 --file-type = wav 3.wav5 现已记录了我们的热词的三个样本,我们可以继续将其发送到 Snowboy 服务。
这是我们在本教程前面编写的 Python 脚本很方便的地方。我们需要调用 Python 文件,并参考我们的三个记录以及处理后的样本的所需输出名称。
我们的 python 脚本将处理文件,生成文件的 base64 编码版本,并将其与其他信息捆绑在一起,然后发送给 Snowboy ,等待它们的响应。
运行以下命令将您的三个样本发送到培训服务。
python3 training_service.py 1.wav 2.wav 3.wav saved_model.pmdl6 在使用新模型之前,应将其复制到 Snowboy 文件夹中,这将使本指南后面的 Python 脚本中使用起来更加容易。
要复制文件,我们可以运行以下两个命令。
第一个命令将复制模型文件,第二个命令将把我们移至 snowboy 目录。
cp saved_model.pmdl ./snowboy/saved_model.pmdl
cd snowboy7 为了测试我们的新模型,我们将使用 snowboy 随附的 demo.py 脚本。该脚本使我们可以指定我们要使用的模型。
只需从当前目录运行以下命令即可启动脚本。
确保您不要以 sudo 身份运行此脚本,因为这会导致我们从麦克风中读取内容,因为我们为 Pi 用户设置了.asoundrc 配置文件。
python demo.py saved_model.pmdl8 加载演示 Python 脚本时,您可能会遇到各种错误消息。其中大多数都是可以忽略的,您可以继续使用演示而不会出现任何问题。
如果您在命令行中看到错误消息” IOError:\ [Errno -9997] 无效的采样率”,请确保已按照本教程前面的说明正确设置了.asoundrc 文件,并且您正在使用可以以 16,000 HZ 录制的麦克风。大多数 USB 麦克风都可以。
如果一切正常,您应该在命令行中看到以下消息,并且可以说出自己的口号。
收听中...按 Ctrl + C退出9 听到您的热词后,您应该看到以下消息出现在命令行中,并通过音频听到蜂鸣声。
此消息表明 snowboy 成功识别了您所说的内容,并触发了其回调函数。
INFO:snowboy:在时间检测到关键字 1 :2018-09-26 04:38:4110 在下一节中,我们将探讨如何在简单的 Python 脚本中实现 Snowboy ,以使您了解如何在项目中利用它。
在 Python 脚本中使用 Snowboy
1 对于 Snowboy 教程的这一部分,我们将编写一个简单的 Python 脚本,该脚本使用 Snowboy 解码器库加载我们的模型,然后侦听它。
要开始编写脚本,只需在树莓派的终端中运行以下命令。为了我们的目的,我们将这个 Python 脚本称为”snowboy_sample.py“。
我们在 snowboy 文件夹中创建此文件,否则我们将无法访问 snowboydecoder 类。原因是 Python 的导入功能仅搜索 python 路径和本地目录。
vim /home/pi/snowboy/snowboy_sample.py2 在此文件中,输入以下代码行。
我们将逐步解释每行代码的作用。如果您希望跳过说明,则可以进行下一步以将代码复制为一个块。
导入 snowboydecoder 第一行代码"导入"snowboydecoder ,因此我们可以访问其功能。此类将处理并处理我们的语音模型。
defdetected_callback():
打印("检测到热门字词")这两行定义了我们的回调函数。该函数很简单,因为只要被调用,它就只会在命令行中打印文本” Hotword Detected “。
探测器= snowboydecoder.HotwordDetector("saved_model.pmdl",灵敏度= 0.5,音频增益= 1)这条线是我们最重要的一条线,因为它实例化了我们的单词检测器。要实现此功能,我们需要传递一些信息。
首先是我们的” 语音模型” 的位置。在我们的例子中,它位于同一目录中,因此我们可以传入文件名。
下一个参数是” 敏感性”。此参数定义触发您的关键词的难易程度。
该值越接近”1”,关键字就需要越不准确。
该值越接近”0”,则必须与原始记录越精确。
如果误报过多或难以触发热词,请增加或减小灵敏度值。
我们定义的最后一个参数是”audio_gain”。此参数确定应将多少增益应用于输入音量,大于 1 的值将增大增益,小于 1 的值将减小增益。
如果您很难用麦克风听,请摆弄这个值。
detector.start(detected_callback)最后一行使用在上一行实例化的检测器,并告诉它开始监听。
我们传入我们编写的函数的名称,因为检测器在每次听到您的热词时都会自动调用此函数。此功能将持续运行直到终止。
3 在 Python 脚本中输入所有这些行后,您可以将其与下面的内容进行比较,以确保您正确输入了所有内容。
导入 snowboydecoder
defdetected_callback():
打印("检测到热门字词")
探测器= snowboydecoder.HotwordDetector("saved_model.pmdl",灵敏度= 0.5,音频增益= 1)
detector.start(detected_callback)4 完成后,按以下键保存文件:CTRL + X,然后按 Y ,最后按 ENTER 。
5 现在编写了脚本,我们可以进行测试以查看其是否正常运行。
要运行该脚本,您需要做的就是在命令行中输入以下行。
python snowboy_sample.py6 现在,每次您说出热门单词时,命令行中都会显示文本” Hotword Detected “,因为它将自动调用我们编写的”detected_callback ():`” 函数。
您可以通过按 CTRL + C 退出此脚本。
可以想象,这在将来可能做的任何项目中都是强大的工具。每当听到某个关键字时,都可以让 Python 触发任务。
我希望到本教程结束时,您已经能够使用 Snowboy 服务记录您自己的自定义关键词。我也希望您已了解如何将 Snowboy 实施到自己的 Pi 项目中,以使用自己的自定义热词。
如果您对此树莓派 Snowboy 热门单词检测教程有任何反馈,请随时在下面给我们留下评论。